좋았던 점
금요일에 교육 듣는사람들과 회식을 하는 자리는 가졌습니다. 다른 사람들과 더욱 친해지는 시간이었던거 같습니다. 또한 교육 자리 바꾸었지만 저는 현재 자리 그대로 나왔습니다. 여러므로 장점이 많은 자리라 매우 만족중입니다. 코딩테스트 하노이탑 문제에서 애를 먹었지만 결국 완전히 이해하고 제것으로 만들고 푼거 같아 뿌듯했습니다. 인스타 릴스로 귀여운 강아지 영상만 보다보니 이제는 강아지 영상만 나오는거 같습니다(쉬는 시간에 보면 힐링이 됩니다).
아쉬웠던 점
이번주는 운동을 많이 못한거 같아 다음주는 좀더 노력해야 할 거 같습니다. 트레이너분이 운동 안하는 사람이 이렇게 기초대사량이 높은거 처음본다고 많이 먹으라고 하셨습니다. 앞으로는 자주 이것저것 먹어줘야 할 거 같습니다. 수업 또한 타자치기 바뻐 이해하는 시간을 많이 갖지 못한거 같습니다. 앞으로는 타자치기 보다는 이해하는 시간을 더 늘려볼까 합니다.
인상적이었던 점
금주에 또다시 대통령의 탄핵이 결정되었습니다. 제 인생에서 2번째 탄핵입니다. 요즘 커서가 좋다는 이야기는 많이 들었지만 이정도로 좋을지는 몰랐습니다. 고민을 해보다가 유료 결제를 할까 합니다. 금일 자작곡 유튜브를 찾았는데 매일 여러곡을 올립니다. AI작업과 사람 작업을 섞어 만드는거 같은데 퀄리티가 매우 좋아 놀랐습니다. 자주 들으며 공부할 거 같습니다. 구글 colab용량을 다 채워 이번주 부터는 두번째 계정에서 공부하는 중입니다. 나름 여러므로 공부를 열심히 하고 있는거 같다는 생각이 들어 뿌듯합니다(공부 외에 것도 많습니다만...).
벌써 4월인게 놀랍습니다.
수업 내용중 어렵거나 중요하다고 생각한 내용 (중요하지만 원래 아는 내용은 스킵하였습니다)
1. 스케일링 기준 train에만 적용

train데이터에 fit_trainsform을 적용해 fit과 적용을 동시에 하고 test를 train이 fit된 스케일기법을 적용만 합니다.
2. PCA(주성분 분석)

pca는 주성분 분석을 하기 위해 사용하는 라이브러리로 데이터가 많고 복잡하면 그중 핵심 특징만 뽑아 단순화 하는 기능을 합니다. 위는 n_components를 2로 설정하여 2개의 주성분만 뽑는 코드입니다. 차원을 축소한 후 복구하면 노이즈를 제거하는 효과도 볼 수 있습니다.
3. 모델 출력층의 output의 shape

마지막 출력층의 Dense layer의 출력이 10이여만 하는 이유는 예측할 클래스의 개수가 10개이기 때문입니다.
또한 MaxPool2D layer의 기본값으로만 적용하면 출력층이 1/2 가 되어 나옵니다.
cnn의 커널 사이즈를 3,3 을 주면 32-(3-1)인 30,30이 나오면 32번 했기에 30,30,32가 나옵니다. 32-(3-1)인 이유는 32*32 크기의 픽셀을 3*3커널로 훑고가며 계산하면 30개가 나오기 때문입니다.
4. next(iter(x))

iter함수는 반복가능한 객체(iterable)를 반복자(iterator)로 바꿔주는 함수입니다. 이로서 next()함수를 사용하여 데이터를 한번씩 가져 올 수 있습니다.DataLoader의 batch사이즈 만큼만 가져오고 shffle=True 이면 매번 랜덤하게 가져옵니다.
5. map 함수

train_df['text']에 전처리 함수를 map을 이용해 적용하는 이유는 시리즈 각 요소 하나하나에 함수를 적용하기 위함입니다. 즉 text_df['text'] 문장을 하나씩 받아와 처리하게 됩니다.
6. vocab_size에 +1을 하는 이유

tokenizer.word_index는 {'이': 1, '영화는': 2, '재미': 3, '있었어요': 4, ...} 와 같이 각 단어에 부여된 정수 인덱스 딕셔러니 입니다. 여기에 +1을 해주는 이유는 패딩을 하게되면 단어가 없는 공간에는 0이 들어와 한게 늘어나기 때문입니다. 0번을 포함한 총 단어수를 지정하는 일입니다.
위 코드와 같이 input_dim을 줄때 사용합니다. output_dim은 보통 작은 데이터셋은 16,32,64정도를 사용하고 큰 모델은 128,256,300(Word2Vec은 300차원이 일반적) 이라고 합니다.
7. RNN, LSTM, GRU 의 비교

세 모델은 시퀀스 모델 즉 시계열 데이터를 처리하는 모델들로 RNN의 장기 기억을 못하는 문제로 인해 LSTM이 나왔고 그로 인해 중요한 정보들만 장기 기억 할 수 있게 되었습니다. GRU은 LSTM의 간단한 버전으로 성능은 비슷하지만 연산을 좀 더 효율적으로 하는 버젼입니다. LSTM의 cell state는 기억을 저장하는 진짜 공간입니다.
결론 : 실무에서는 GRU의 인기가 제일 많습니다.
8. 활성화 함수
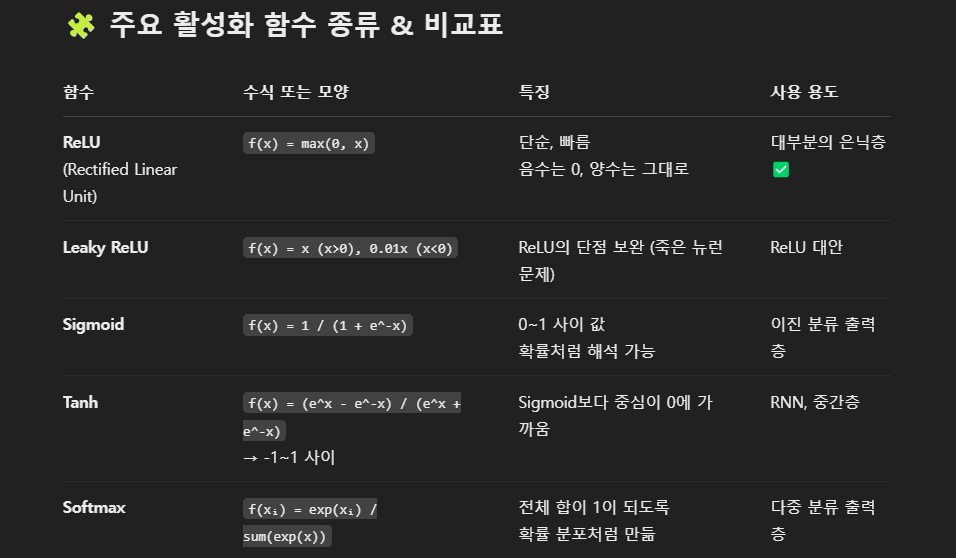
활성화 함수의 종류와 계산식, 사용방법은 위 사진과 같습니다.

활성화 함수는 뉴련의 출력값을 비선형적으로 변경해주는 함수입니다. 선형함수는 사용하면 딥러닝도 결국 그냥 선형 모델일 뿐입니다(표현력이 떨어짐). 위와 같은 비선형적으로 변경해주는 활성 함수를 적용해 더욱 복잡한 문제를 해결 가능하게 되었습니다.
금주의 이모티콘(금주의 나의 상태를 제일 잘 표현하는 이모티콘)

'skn family ai camp' 카테고리의 다른 글
| skn family ai campskn 8 주차 회고록(2025.04.014-2025.04.18) (2) | 2025.04.19 |
|---|---|
| skn 7 주차 회고록(2025.04.07-2025.04.11) (1) | 2025.04.12 |
| skn 5 주차 회고록(2025.03.24-2025.03.28) (1) | 2025.03.29 |
| skn 4 주차 회고록(2025.03.17-2025.03.21) (0) | 2025.03.22 |
| skn 3 주차 회고록(2025.03.10-2025.03.14) (0) | 2025.03.16 |